Pealt 7000 raamatu sai kirja – ootel veel umbes tuhatkond Loomingu Raamatukogu.
Ei viitsind neid käsitsi sisse toksida, seepärast otsisin, kust leiaks – tean et on olemas LR Bibliograafia.
LR 60 bibliograafia leiab siit: http://www.loominguraamatukogu.ee/wp-content/uploads/2017/02/LRbiblio.pdf

Väga kena, aga mul oleks vaja sealt need raamatud ja nimed ja muu vajalik tabelisse saada. Saaks otsida ja filtreerida ja märkida, mis mul puudu jne.
Copy-Paste sealt väga ei õnnestu ja mulle väga ei meeldi ka. Seepärast võtsin oma vana sõbra Exceli ja palusin tal mulle vajalik sealt sisse lugeda. Utlesin, et mul on selline PDF ja tahaks sealt andmed kätte saada.

Kõrvalaknas uurisin natuke seda ja katsetasin – seal umbes 93 lkst alates ja leheküljeni 147 on ilus kronoloogiline loetelu (mul kahjuks aastad 1957-2000, hilisemaid ei ole – muidu see loetelu leheküljeni 164)
Selleks filtreerin välja ainult leheküljed (tabelid on seal vaid päised ja jalused), teisendan Page006 → 6 täisarvuks ja lisan filtri – anna vaid lehed 93-147

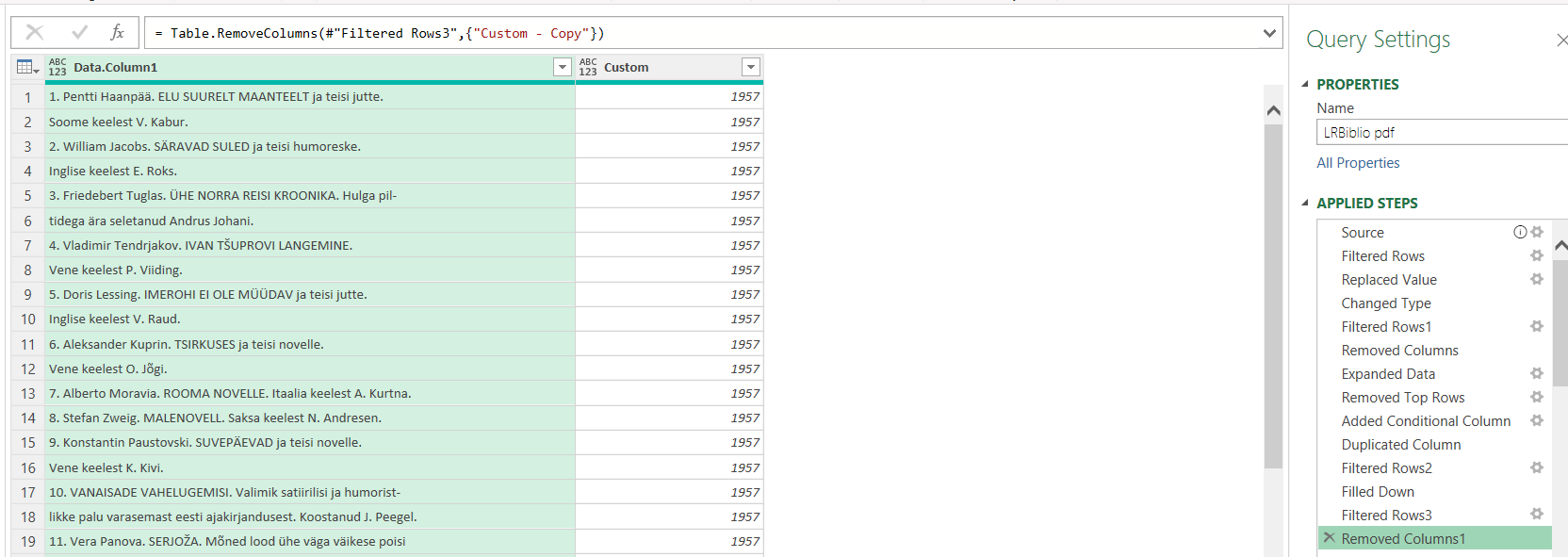
Seejärel eemaldan ülearused veerud ja teisendan sisu tabeli kujule:

Nüüd on vaja mõned read eemaldada – alguserida ja lehenumbrid. Selleks teen väikese abivahendi – veeru, kus neile ridadele, kus arv pannakse see arv (arvuna) ja mujale pannakse null ning eemaldan nii kõik read, kus arv < 1000 (lehenumbrid) arvud üle 1000 panen eraldi veergu ja täidan alla, nii saan igale väljaande aasta külge
Mängimist kui palju, aga toredam, kui 1000 raamatut sisse toksida
Nüüd otsin välja kõik read, mis algavad numbriga. Nimelt sealt tabelist tulevad mõned väljaanded ühe, mõned mitmerealisena ja need oleks vaja kokku saada. Ära tunnen ma nad selle järgi, kus alguses on number.
Sellest üksi ei piisanud – ühes väljaandes oli rea alguses 1870 – see oli paraku pealkirja osa, sellest sain ka ikkagi jagu
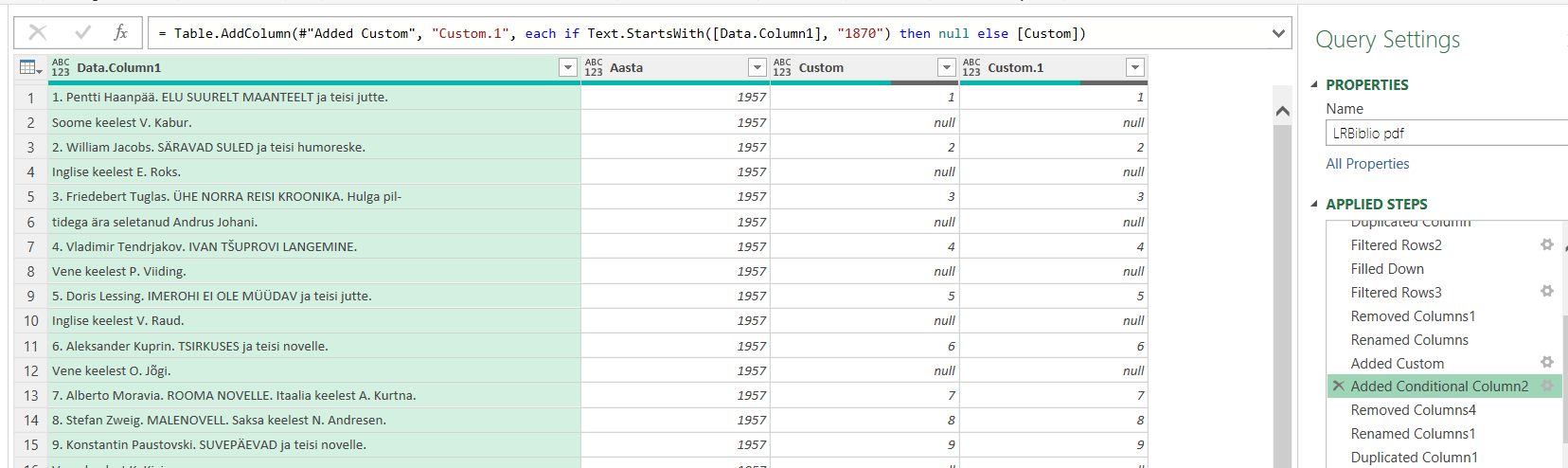
Ülearused veerud minema, mõned lisaarvutused ja tükeldus. Nii saan pealkirjade eest väljaande numbri kätte.
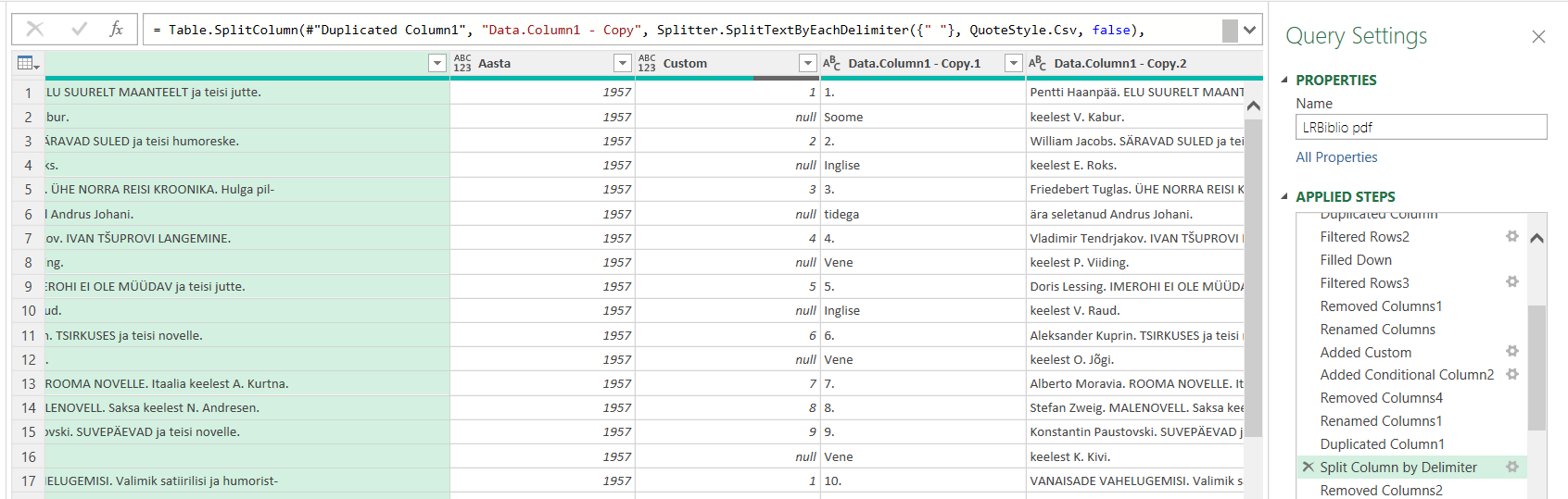
veel paar teisendust ja mul tabel, kus pealkirjad (mitmel real), aasta ja väljaanne. Lisaks tegin vaal paar kavalat teisendust, et pärast poolitusmärgid kätte saada ja eemaldada
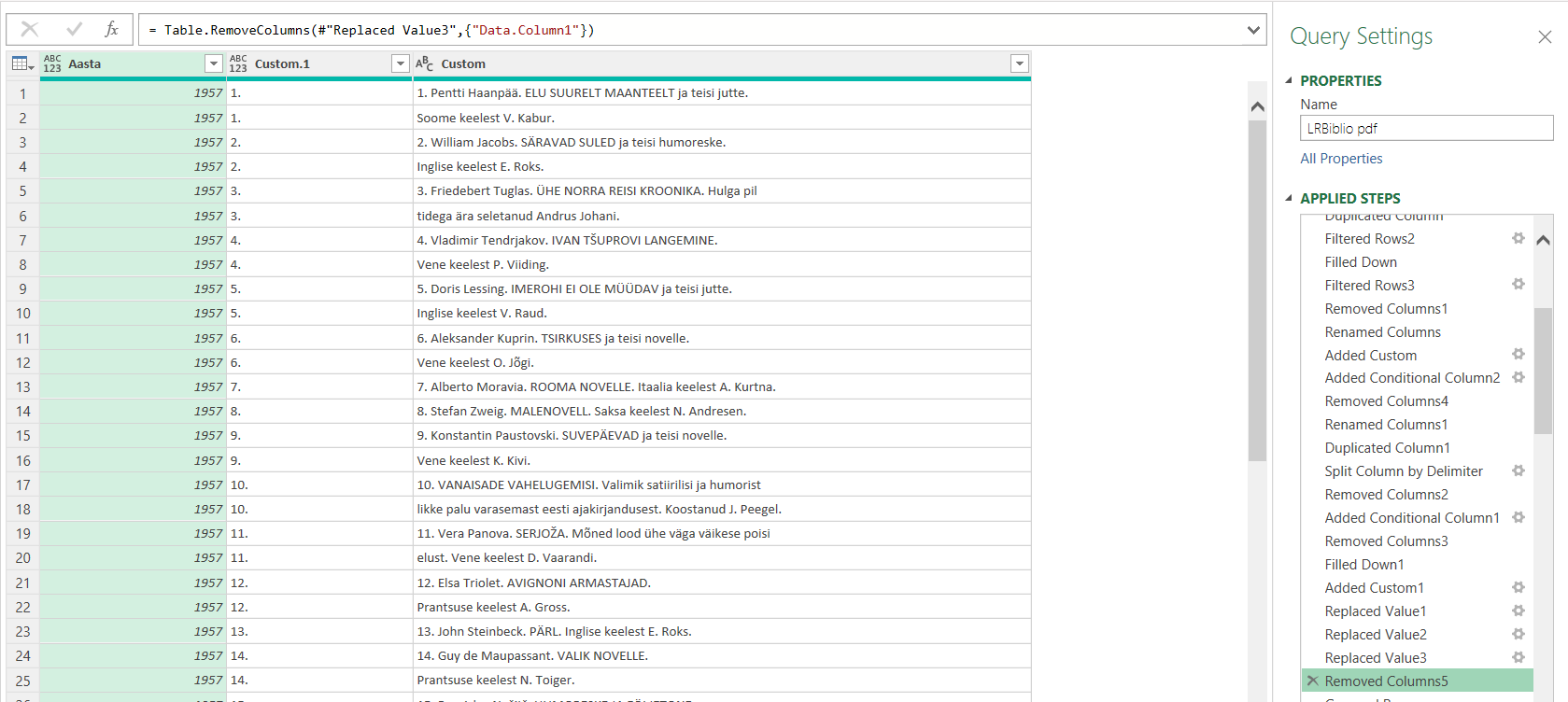
Järgmiseks tegin grupeerimistehte, kus pealkirja read ilusti üheks sain.

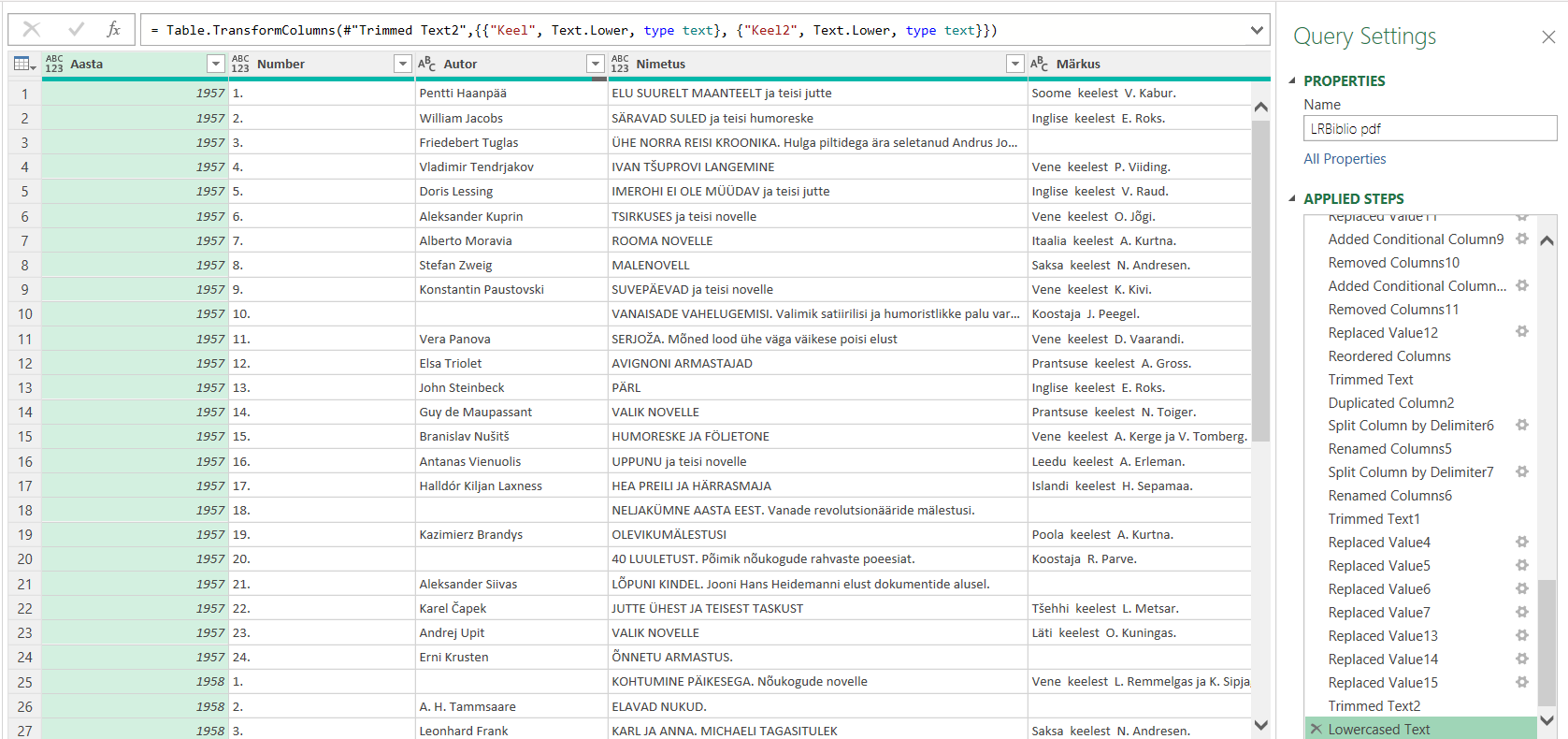
Sealt pealkirjade eest on nüüd vaja need numbrid ära saada – see on lihtne, järgmine on aga keeruline vigur. Osa väljaandeid on autoriga, osa ilma. Õnneks on selle LRBiblio koostaja taibanud pealkirjad kirjutada üleni suurte tähtedega. Selle järgi tunnen ära ja tegutsen. Ei hakka iga sammu selgitama, aga tulemus sai selline:

Edasi uurisin natuke pealkirja järel olevat kommentaari – seal on variante kogunud, kogunud ja tõlkinud, kui tõlkinud, siis mis keelest. Mõni keel on ühesõnaline, mõni aga kahe-. Neid variante teisendades sain lõpuks tabeli, kus nii koguja, tõlkija, mis keelest jms
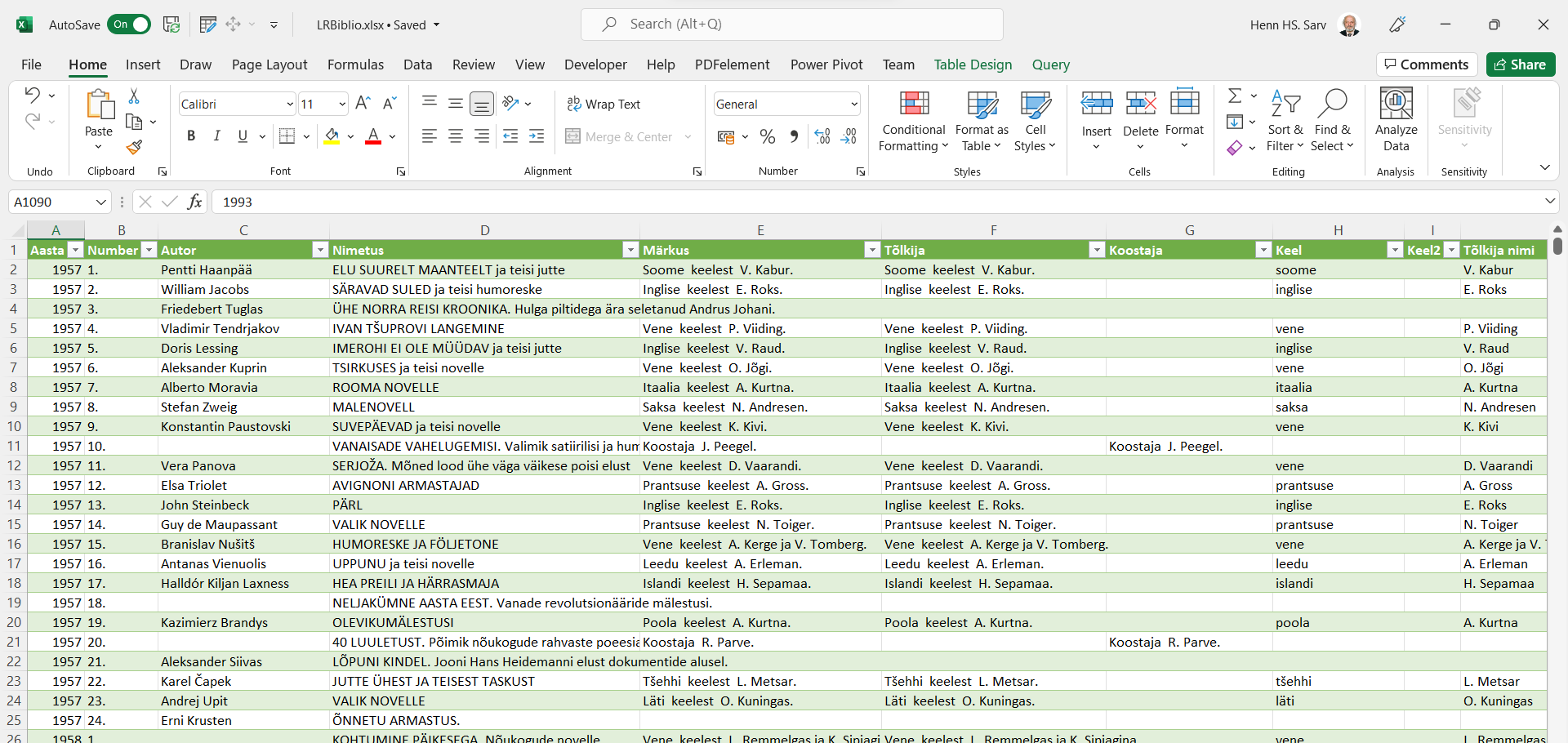
Ja selle tabeli siis laadisin juba Excelisse ja töö tehtud.
Oli palju lõbusam, kui 1000 nimetust käsitsi tabelisse kanda.
ja kui veel mõni tahab ise ka proovida, siis siin on kogu selle tegevuse käigus “iseenesest” tekkinud programmi- või päringukood. Seda ilusamaks ei viitsinud tegema hakata, kuigi oleks võinud:
// http://www.loominguraamatukogu.ee/wp-content/uploads/2017/02/LRbiblio.pdf
let
// Source = Pdf.Tables(File.Contents("D:\OneDrive\ExtendedKodu\SQL Books\Free-Ebook\LRbiblio.pdf"), [Implementation="1.3"]),
Source = Pdf.Tables(Web.Contents("http://www.loominguraamatukogu.ee/wp-content/uploads/2017/02/LRbiblio.pdf"), [Implementation="1.3"]),
#"Filtered Rows" = Table.SelectRows(Source, each ([Kind] = "Page")),
#"Replaced Value" = Table.ReplaceValue(#"Filtered Rows","Page","",Replacer.ReplaceText,{"Id"}),
#"Changed Type" = Table.TransformColumnTypes(#"Replaced Value",{{"Id", type number}}),
#"Filtered Rows1" = Table.SelectRows(#"Changed Type", each [Id] >= 93 and [Id] 1000 or [Custom] = null),
#"Filled Down" = Table.FillDown(#"Filtered Rows2",{"Custom"}),
#"Filtered Rows3" = Table.SelectRows(#"Filled Down", each [#"Custom - Copy"] <> [#"Custom"]),
#"Removed Columns1" = Table.RemoveColumns(#"Filtered Rows3",{"Custom - Copy"}),
#"Renamed Columns" = Table.RenameColumns(#"Removed Columns1",{{"Custom", "Aasta"}}),
#"Added Custom" = Table.AddColumn(#"Renamed Columns", "Custom", each try Number.FromText(Text.Middle([Data.Column1],0,1)) otherwise null),
#"Added Conditional Column2" = Table.AddColumn(#"Added Custom", "Custom.1", each if Text.StartsWith([Data.Column1], "1870") then null else [Custom]),
#"Removed Columns4" = Table.RemoveColumns(#"Added Conditional Column2",{"Custom"}),
#"Renamed Columns1" = Table.RenameColumns(#"Removed Columns4",{{"Custom.1", "Custom"}}),
#"Duplicated Column1" = Table.DuplicateColumn(#"Renamed Columns1", "Data.Column1", "Data.Column1 - Copy"),
#"Split Column by Delimiter" = Table.SplitColumn(#"Duplicated Column1", "Data.Column1 - Copy", Splitter.SplitTextByEachDelimiter({" "}, QuoteStyle.Csv, false), {"Data.Column1 - Copy.1", "Data.Column1 - Copy.2"}),
#"Removed Columns2" = Table.RemoveColumns(#"Split Column by Delimiter",{"Data.Column1 - Copy.2"}),
#"Added Conditional Column1" = Table.AddColumn(#"Removed Columns2", "Custom.1", each if [Custom] = null then null else [#"Data.Column1 - Copy.1"] ),
#"Removed Columns3" = Table.RemoveColumns(#"Added Conditional Column1",{"Custom", "Data.Column1 - Copy.1"}),
#"Filled Down1" = Table.FillDown(#"Removed Columns3",{"Custom.1"}),
#"Added Custom1" = Table.AddColumn(#"Filled Down1", "Custom", each [Data.Column1]&"XXXXXX"),
#"Replaced Value1" = Table.ReplaceValue(#"Added Custom1","-XXXXXX","yyyyyy",Replacer.ReplaceText,{"Custom"}),
#"Replaced Value2" = Table.ReplaceValue(#"Replaced Value1","yyyyyy","",Replacer.ReplaceText,{"Custom"}),
#"Replaced Value3" = Table.ReplaceValue(#"Replaced Value2","XXXXXX"," ",Replacer.ReplaceText,{"Custom"}),
#"Removed Columns5" = Table.RemoveColumns(#"Replaced Value3",{"Data.Column1"}),
#"Grouped Rows" = Table.Group(#"Removed Columns5", {"Aasta", "Custom.1"}, {{"Koos", each Text.Combine([Custom]), type nullable text}}),
#"Split Column by Delimiter1" = Table.SplitColumn(#"Grouped Rows", "Koos", Splitter.SplitTextByEachDelimiter({" "}, QuoteStyle.Csv, false), {"Koos.1", "Koos.2"}),
#"Removed Columns6" = Table.RemoveColumns(#"Split Column by Delimiter1",{"Koos.1"}),
#"Added Conditional Column3" = Table.AddColumn(#"Removed Columns6", "Custom", each if Text.At([Koos.2],1) = Text.Upper(Text.At([Koos.2],1)) and Text.At([Koos.2],1) <> "." then ". "&[Koos.2] else [Koos.2]),
#"Removed Columns7" = Table.RemoveColumns(#"Added Conditional Column3",{"Koos.2"}),
#"Renamed Columns2" = Table.RenameColumns(#"Removed Columns7",{{"Custom.1", "Number"}}),
#"Added Conditional Column11" = Table.AddColumn(#"Renamed Columns2", "Custom.1", each if Text.Middle([Custom],4,2) = ". " then Text.ReplaceRange([Custom],4,2, "@") else [Custom]),
#"Added Custom2" = Table.AddColumn(#"Added Conditional Column11", "Custom.2", each if Text.Middle([Custom.1],1,2) = ". " then Text.ReplaceRange([Custom.1],1,2, "@") else [Custom.1]),
#"Removed Columns12" = Table.RemoveColumns(#"Added Custom2",{"Custom", "Custom.1"}),
#"Renamed Columns7" = Table.RenameColumns(#"Removed Columns12",{{"Custom.2", "Custom"}}),
#"Split Column by Delimiter2" = Table.SplitColumn(#"Renamed Columns7", "Custom", Splitter.SplitTextByEachDelimiter({". "}, QuoteStyle.Csv, false), {"Custom.1", "Custom.2"}),
#"Renamed Columns3" = Table.RenameColumns(#"Split Column by Delimiter2",{{"Custom.1", "Autor"}, {"Custom.2", "Nimetus ja märkus"}}),
#"Replaced Value8" = Table.ReplaceValue(#"Renamed Columns3","Valinud ja ","Valinud£ja£",Replacer.ReplaceText,{"Nimetus ja märkus"}),
#"Replaced Value16" = Table.ReplaceValue(#"Replaced Value8","@",". ",Replacer.ReplaceText,{"Autor"}),
#"Replaced Value9" = Table.ReplaceValue(#"Replaced Value16","Klassikalisest ","Klassikalisest£",Replacer.ReplaceText,{"Nimetus ja märkus"}),
#"Replaced Value10" = Table.ReplaceValue(#"Replaced Value9","(I) ","(I)£",Replacer.ReplaceText,{"Nimetus ja märkus"}),
#"Added Conditional Column4" = Table.AddColumn(#"Replaced Value10", "Custom", each if Text.Contains([Nimetus ja märkus], "keelest") then [Nimetus ja märkus] else null),
#"Split Column by Delimiter3" = Table.SplitColumn(#"Added Conditional Column4", "Custom", Splitter.SplitTextByEachDelimiter({"keelest"}, QuoteStyle.Csv, false), {"Custom.1", "Custom.2"}),
#"Split Column by Delimiter4" = Table.SplitColumn(#"Split Column by Delimiter3", "Custom.1", Splitter.SplitTextByEachDelimiter({"."}, QuoteStyle.Csv, true), {"Custom.1.1", "Custom.1.2"}),
#"Added Conditional Column5" = Table.AddColumn(#"Split Column by Delimiter4", "Nimetus1", each if [Custom.1.1] = null then [Nimetus ja märkus] else [Custom.1.1]),
#"Removed Columns8" = Table.RemoveColumns(#"Added Conditional Column5",{"Nimetus ja märkus"}),
#"Added Conditional Column6" = Table.AddColumn(#"Removed Columns8", "Custom", each if [Custom.1.1] = null then null else [Custom.1.2 ] & " keelest " & [Custom.2]),
#"Removed Columns9" = Table.RemoveColumns(#"Added Conditional Column6",{"Custom.1.1", "Custom.1.2", "Custom.2"}),
#"Renamed Columns4" = Table.RenameColumns(#"Removed Columns9",{{"Custom", "Tõlkija"}}),
#"Added Conditional Column7" = Table.AddColumn(#"Renamed Columns4", "Custom", each if Text.Contains([Nimetus1], "Koostanud") then [Nimetus1] else null),
#"Split Column by Delimiter5" = Table.SplitColumn(#"Added Conditional Column7", "Custom", Splitter.SplitTextByDelimiter("Koostanud", QuoteStyle.Csv), {"Custom.1", "Custom.2"}),
#"Added Conditional Column8" = Table.AddColumn(#"Split Column by Delimiter5", "Koostaja", each if [Custom.2] = null then null else "Koostaja " & [Custom.2]),
#"Replaced Value11" = Table.ReplaceValue(#"Added Conditional Column8","(I)£","",Replacer.ReplaceText,{"Tõlkija"}),
#"Added Conditional Column9" = Table.AddColumn(#"Replaced Value11", "Nimetus", each if [Custom.1] = null then [Nimetus1] else [Custom.1]),
#"Removed Columns10" = Table.RemoveColumns(#"Added Conditional Column9",{"Custom.1", "Custom.2"}),
#"Added Conditional Column10" = Table.AddColumn(#"Removed Columns10", "Märkus", each if [Tõlkija] = null then [Koostaja] else [Tõlkija]),
#"Removed Columns11" = Table.RemoveColumns(#"Added Conditional Column10",{"Nimetus1"}),
#"Replaced Value12" = Table.ReplaceValue(#"Removed Columns11","£"," ",Replacer.ReplaceText,{"Märkus"}),
#"Reordered Columns" = Table.ReorderColumns(#"Replaced Value12",{"Aasta", "Number", "Autor", "Nimetus", "Märkus", "Tõlkija", "Koostaja"}),
#"Trimmed Text" = Table.TransformColumns(#"Reordered Columns",{{"Märkus", Text.Trim, type text}, {"Tõlkija", Text.Trim, type text}, {"Koostaja", Text.Trim, type text}}),
#"Duplicated Column2" = Table.DuplicateColumn(#"Trimmed Text", "Tõlkija", "Tõlkija - Copy"),
#"Split Column by Delimiter6" = Table.SplitColumn(#"Duplicated Column2", "Tõlkija - Copy", Splitter.SplitTextByEachDelimiter({" "}, QuoteStyle.Csv, false), {"Tõlkija - Copy.1", "Tõlkija - Copy.2"}),
#"Renamed Columns5" = Table.RenameColumns(#"Split Column by Delimiter6",{{"Tõlkija - Copy.1", "Keel"}}),
#"Split Column by Delimiter7" = Table.SplitColumn(#"Renamed Columns5", "Tõlkija - Copy.2", Splitter.SplitTextByDelimiter("keelest", QuoteStyle.Csv), {"Tõlkija - Copy.2.1", "Tõlkija - Copy.2.2"}),
#"Renamed Columns6" = Table.RenameColumns(#"Split Column by Delimiter7",{{"Tõlkija - Copy.2.1", "Keel2"}, {"Tõlkija - Copy.2.2", "Tõlkija nimi"}}),
#"Trimmed Text1" = Table.TransformColumns(#"Renamed Columns6",{{"Keel2", Text.Trim, type text}, {"Tõlkija nimi", Text.Trim, type text}}),
#"Replaced Value4" = Table.ReplaceValue(#"Trimmed Text1",". ","#",Replacer.ReplaceText,{"Tõlkija nimi"}),
#"Replaced Value5" = Table.ReplaceValue(#"Replaced Value4",".","",Replacer.ReplaceText,{"Tõlkija nimi"}),
#"Replaced Value6" = Table.ReplaceValue(#"Replaced Value5","#",". ",Replacer.ReplaceText,{"Tõlkija nimi"}),
#"Replaced Value7" = Table.ReplaceValue(#"Replaced Value6","",null,Replacer.ReplaceValue,{"Keel2"}),
#"Replaced Value13" = Table.ReplaceValue(#"Replaced Value7","Valinud£ja£","",Replacer.ReplaceText,{"Keel"}),
#"Replaced Value14" = Table.ReplaceValue(#"Replaced Value13","£"," ",Replacer.ReplaceText,{"Keel"}),
#"Replaced Value15" = Table.ReplaceValue(#"Replaced Value14","ja ","",Replacer.ReplaceText,{"Keel2"}),
#"Trimmed Text2" = Table.TransformColumns(#"Replaced Value15",{{"Keel", Text.Trim, type text}, {"Keel2", Text.Trim, type text}}),
#"Lowercased Text" = Table.TransformColumns(#"Trimmed Text2",{{"Keel", Text.Lower, type text}, {"Keel2", Text.Lower, type text}})
in
#"Lowercased Text"
Kood töötab igas masinas. Ma tegin selle küll allalaetud faili peal, aga päringu teisendasin onlinest võetava PDFi tarbeks.
Rõhutan, et nii ei pea tegema, aga võib